At Appgate Threat Advisory Services, we focus on offensive security research to keep up to date with the constantly evolving cybersecurity landscape. We believe in understanding offensive techniques and trends to provide great defensive solutions.
In this post I aim to shed some light on remote kernel exploitation, through the lens of a recent remote stack overflow (CVE-2022-0435) discovered by our Threat Advisory Services team. I noticed when working on this bug that the information available on kernel remotes is fairly sparse, compared to the amazing wealth of high-quality write-ups we have in the local privilege escalation (LPE) space.
By covering the various steps involved in writing up this kernel remote, I hope to provide some fresh insights on remote Linux kernel exploitation and highlight the similarities and differences to local exploitation.
Background
For a bit of context, when I joined Appgate Threat Advisory Services in December, my team lead suggested I kick things off by exploring two neat Linux bugs. Both had existing proof-of-concepts (PoCs) for LPE, however one was a heap overflow which also happened to be remotely reachable [0], though there were no remote PoCs.
Of course, being a new employee and wanting to make a good impression, I played it safe and stuck with the LPE ... nah, who am I kidding? Of course, I couldn't resist the temptation of a remote kernel exploit!
Talk about trial by fire (albeit totally self-inflicted), but one new vulnerability and a lot of breakpoints later, I'm happy to be able to write this post with the aim of sharing some of my work and contributing to an awesome community.
Setting the scene
Alright, enough of the pleasantries, let's get into some technicals! As I mentioned previously, we're going to be looking at my work on CVE-2022-0435, so it's probably a good idea to cover what exactly this is.
CVE-2022-0435 is a remotely triggerable stack overflow in the Transparent Inter-Process Communication (TIPC) networking module of the Linux kernel. We're basically able to send a payload of attacker-controlled size to the target, where it will be memcpy'd into a 272-byte buffer on the kernel's stack—not a bad primitive, right?
There's a little more nuance to it than that and we'll touch on the payload constraints shortly, but that's the general gist of it. For more information on TIPC and a more detailed look at the bug, you can check out my last post [1].
The "payload" we're sending is masquerading as a domain record, which is transferred between TIPC nodes to share views of network topology. Here's the structure definition:
#define MAX_MON_DOMAIN 64
...
/* struct tipc_mon_domain: domain record to be transferred between peers
* @len: actual size of domain record
* @gen: current generation of sender's domain
* @ack_gen: most recent generation of self's domain acked by peer
* @member_cnt: number of domain member nodes described in this record
* @up_map: bit map indicating which of the members the sender considers up
* @members: identity of the domain members
*/
struct tipc_mon_domain {
u16 len;
u16 gen;
u16 ack_gen;
u16 member_cnt;
u64 up_map;
u32 members[MAX_MON_DOMAIN];
};
But Sam, that struct is clearly 272 bytes? You would be correct to assume so! And that's where the vulnerability lies. When these domain records are received by the module's tipc_mon_rcv(), it doesn't check that member_cnt <= MAX_MON_DOMAIN; this essentially allows attackers to submit these elastic objects as if we had u32 members[member_cnt].
Later, when the domain records are cached as new ones come in, TIPC goes to copy this arbitrarily sized domain record into a stack buffer expected at most 272 bytes—and that's our stack overflow.
With that covered, let's touch on the constraints of our payload:
- len, gen, ack_gen and member_cnt values are all constrained
- However, up_map and members can be arbitrary
- Payload size is defined by len and member_cnt and is constrained by the Maximum Transmission Unit (MTU) of the protocol we are using to send the payload; though as we'll touch on later, this is likely much shorter if we want to hand execution cleanly back to the kernel
- Provided we haven't already caused a kernel panic, we're able to trigger the bug multiple times
Pwning glossary
In a bid to make this wall of text a little bit more accessible, here are some resources to relevant techniques/mitigations as well as common terminology:
- LPE: Local Privilege Escalation: exploiting a target with local user access
- RCE: Remote Code Execution: exploiting a target remotely
- ROP: Return Oriented Programming; see Code Arcana’s Intro to ROP (2013)
- $RAX: x86_64 volatile register; often used to store a return value
- $RIP: x86_64 instruction pointer register; points to next instruction to execute; 'gaining $RIP control' = control flow hijacking
- $RSP: x86_64 stack pointer; points to the top of the current stack frame
- Stack Smashing: term used for the technique of exploiting a stack buffer overflow; immortalized by the 1998 Phrack article “Smashing The Stack For Fun And Profit” by Aleph One
Game plan
Okay, so we have a pretty nice remote stack overflow primitive, but where do we go from here? Before we can come up with a game plan, let's take stock of the relevant mitigations we are more than likely up against on even a relatively up-to-date kernel:
KASLR: Kernel Address Space Layout Randomization will, perhaps unsurprisingly, randomize the location of the kernel at boot time. For us, this means the address of kernel functions will differ by a pseudo-random offset each time the system is booted. Note the order of the kernel doesn't change, just the kernel base address. [2]
CONFIG_STACKPROTECTOR: Also known as stack canaries, this mitigation adds a pseudo-random value to the stack during the function prologue and checks it is still intact in the epilogue. This canary will sit between a buffer and the return address, meaning any overflow will first corrupt this canary value. If the kernel spots the canary has changed, it'll cause a kernel panic. Game over! [3]
SMEP and SMAP: Supervisor Mode Execution Prevention and Supervisor Mode Access Prevention, respectively, prevent us from executing usermode code and dereferencing usermode pointers while running in the kernel context/ring 0. [4]
We also need to factor in the execution context we'll be hijacking if we successfully overwrite the return address with our remote stack overflow and gain control of execution. Unlike most local exploit scenarios, we won't be operating in the process context, but instead we will find ourselves in the interrupt context.
In local exploitation, we often will reach the vulnerable code path in the kernel via a syscall, where a usermode process can request the kernel perform a privileged action on its behalf (we'll touch more on this later). Processes in Linux are tracked in the kernel via a struct task_struct, which resides on a kernel stack allocated to each process.
When the kernel is doing work on behalf of a usermode process, it operates on the respective kernel stack for the calling process, i.e. within the process context. As we're attacking a target remotely, there is no associated process.
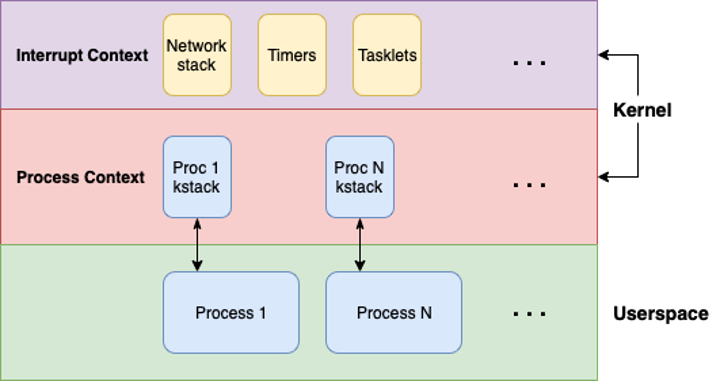
Instead, we send a packet to the target which is then received by the network card. The network card then generates an interrupt to signal a packet has arrived. The flow of execution will then get suspended and the appropriate interrupt handler will run. In our case, the network stack where our stack overflow is triggered runs within this interrupt context.
From an exploitation context that means that while we have execution in the kernel, there's no associated userspace for us to elevate privileges and inject a payload (e.g., a remote listener). Furthermore, the interrupt context comes with some quirks of its own, like the fact there's no context switching (so no sleep, schedule or user memory access).
Yikes, things are starting to look a bit more complicated now. Regardless, we have all the information necessary to put together a game plan for exploiting this remote stack overflow:
- Information leak: first things first, we need to leak a kernel address to bypass KASLR as well as the stack canary to bypass CONFIG_STACKPROTECTOR
- Shellcode execution: after we get control of the return address, we want to leverage our control-flow hijacking primitive to something more flexible; shellcode execution would be nice
- Pivot to process context: next we need to pivot from the interrupt context to the process context, so we actually have a userspace to run our payload in
- Win: after switching to process context, we just need to inject our payload into a root process and voila!
Information leak
dmesg? Uninitialized stack vars in a syscall? msg_msg shenanigans? For a long while, the general consensus has been KASLR is more of a nuisance than a serious mitigation for local exploitation [5]. However, the dynamic changes significantly for remote exploitation; the attack surface is drastically reduced.
Suddenly, the surface is reduced to the parts of the network stack we can reach remotely. Even if we find a bug, we need to be able to have the leak returned to us over the network. This is particularly difficult when we factor in stack canaries, as we limit the scope further to a stack leak within the network stack.
Perhaps unsurprisingly then, the available resources on remote KASLR leaks, let alone canary leaks, is fairly sparse. A recent, notable example being “From IP ID to Device ID and KASLR Bypass.”
As if finding a kernel address plus canary leak and getting it back to us wasn't arduous enough, we also need a way to fingerprint the kernel version running on the target. Without this, we can't really do much with our KASLR leak, as the offsets of kernel symbols vary across images.
For the scope of this post, we're going to assume either the absence of KASLR + CONFIG_STACKPROTECTOR on target, or the presence of a kernel version with a usable remote leak. Needless to say, of our four-point game plan, the first is the hardest obstacle to overcome.
Shellcode execution
Now it's time to get stuck in! With KASLR and CONFIG_STACKPROTECTOR squared away, we're able to trigger our remote stack overflow and overwrite the return address without causing a kernel panic.
If we look at the assembly epilogue for the vulnerable function, several registers are also popped off the stack before the return address, meaning we have full control of those values too. Here's an x86_64 example:
tipc_mon_rcv:
...
<+191>: pop rbx
<+192>: pop r12
<+194>: pop r13
<+196>: pop r14
<+198>: pop r15
<+200>: pop rbp
<+201>: ret
Now that we're able to hijack control flow, what do we want to do with it? Right now, let's focus on what we can't do:
As we're in the interrupt context and we're remote attackers, there's no usermode shellcode we can jump to; not that SMEP & SMAP would let us touch usermode at the moment anyway.
NX Stack: in modern CPUs, the Memory Management Unit (MMU) provides various features. Relevant to us is the presence of an 'NX bit' (non-executable bit) that allows the CPU to mark a page of memory as non-executable. Unfortunately for us, the kernel uses this feature to make our kernel stack non-executable.
This means we can't just include some shellcode in our stack payload and jump to that unless we are able to call a kernel function called set_memory_x()? Thanks to an exploitation technique called Return Oriented Programming (ROP) we can do just that. With control of the instruction pointer, we can call other snippets of legitimate kernel code, chaining them together to do our bidding.
So, the goal here is to create a ROP-chain that will essentially carry out the following pseudocode:
call set_memory_x($RSP & ~0xfff, 1)
jmp $RSP
The function signature is set_memory_x(unsigned long addr, int numpages), where addr must be a page-aligned address. As a result, to find the page our stack payload rests on, we apply a page mask to $RSP.
The reason for the funky argument to set_memory_x() is that it must take a page-aligned pointer and then the number of pages to set as executable. To get the address of the start of the page we're currently on, we apply the page mask (~0xfff for 4k pages).
By utilizing the registers we have control of and tools like ropper to mine for gadgets in a representative kernel image, we can get an executable stack that we can jump execution to. Let's take a moment to visualize what our struct tipc_mon_receive payload looks like:
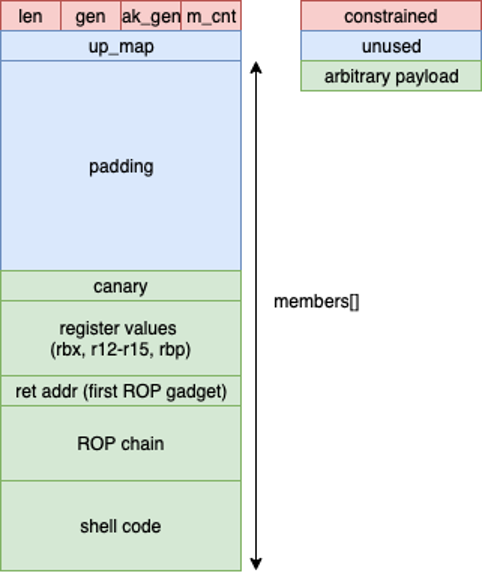
Awesome! Now that we have an executable stack, we have a lot more flexibility as we can include shellcode directly in our payload which will be run by the kernel. We now have room to focus on pivoting to the process context.
Cleanup
Let's not get ahead of ourselves though! Sure, we have shellcode execution, but what good is popping a root payload if the kernel panics as soon as we hand back execution?
Before we go any further, we need to ensure we can cleanly hand execution back to the kernel after we've triggered the stack overflow. Not only is this important to determine the viability of the exploit, but it may also impose additional restrictions on the payload—the earlier we know these the better!
To return execution back to the kernel after our exploit and get things running smoothly again, we need to get an understanding of the state of execution before we hijacked everything. We need to:
- Analyze the stack pre/post overflow; which function's stack frames are we clobbering?
- Determine what is the closest unclobbered stack frame we can return to
- Determine if any locks are released in the functions we skip returning to. If so, we need to release these ourselves
- After we pick a return address, make sure $RSP, $RBP and any other required registers are correct
If we take a look at our backtrace within the vulnerable function, we can begin answering some of these questions:
[#1] 0xffffffffc072dd4c -> tipc_mon_rcv(net=<optimised out>, data=0xffff88810dba7176, dlen=<optimised out>, addr=<optimised out>, state=0xffff88810035848a, bearer_id=<optimised out>)
[#2] 0xffffffffc07274e6 -> tipc_link_proto_rcv(l=0xffff888100358400, skb=0xffff888102036c00, xmitq=0xffffc900000e4cc8)
[#3] 0xffffffffc0727f4e -> tipc_link_rcv(l=0xffff888100358400, skb=0xffff888102036c00, xmitq=0xffffc900000e4cc8)
[#4] 0xffffffffc07388a1 -> tipc_rcv(net=0xffffffff830e5640 <init_net>, skb=<optimised out>, b=<optimised out>)
[#5] 0xffffffffc071ffe9 -> tipc_l2_rcv_msg(skb=0xffff888102036c00, dev=<optimised out>, pt=<optimised out>, orig_dev=<optimised out>)
[#6] 0xffffffff819f3b67 -> __netif_receive_skb_list_ptype(orig_dev=0xffff888102062000, pt_prev=0xffff88810bc3da80, head=0xffffc900000e4d68)
[#7] 0xffffffff819f3b67 -> __netif_receive_skb_list_ptype(orig_dev=0xffff888102062000, pt_prev=0xffff88810bc3da80, head=0xffffc900000e4d68)
[#8] 0xffffffff819f3b67 -> __netif_receive_skb_list_core(head=0xffff888102062a60, pfmemalloc=<optimised out>)
[#9] 0xffffffff819f3d4e -> __netif_receive_skb_list(head=0xffff888102062a60)
After taking into account the general size requirements for our ROP-chain, shellcode and cleanup code and comparing these to the size of the stack frames in our backtrace, we know at the very least we're going to clobber #2, #3 & #4. This means we're realistically looking to hand back execution to #5 onwards.
However, during the clobbered #2 & #4, we actually release some important locks on TIPC objects, so we need to release these ourselves. As TIPC is a loadable module, our KASLR leak doesn't help us here, so to release these locks, we need to fetch a TIPC address off the stack.
This leaves us with #5 as our latest return point, as the last stack frame with a TIPC reference. We can then analyze this and the subsequent functions to check what register values they're expecting. We also now know the amount we need to adjust $RSP & $RBP by.
With the above requirements gathered, we now know the restrictions on our payload size to safely hand back execution, and we can plan the next stages accordingly.
It's also worth noting that we can throw this exploit multiple times. While the ROP chain may take up a reasonable portion of space the first throw, as the stack is deterministic, we only need to make it executable once. Subsequent throws can jump straight to $RSP, giving us more room for our shellcode.
Pivot to process context
Alright, where were we? We've got an executable stack and it's time to write some shellcode. Besides the mandatory cleanup we mentioned above, we want to find a way to pivot to the process context, so we actually have a userspace to pwn.
"How are we going to pivot to the process context?," I hear you ask. Well, the answer is syscall hooking. Earlier, we briefly touched on the fact that syscalls facilitate the interaction between userspace and the kernel, so where better to find ourselves a process.
Syscall primer
Let's take a closer look at how syscalls are handled in Linux and how we might be able to leverage this to our advantage. For anyone unfamiliar, system calls are the fundamental interface between user processes and the kernel. If a user process needs the kernel to do something on its behalf, it can ask via a syscall.
We covered in passing the idea of interrupts, for example a hardware interrupt being generated by your network card when it receives a packet. Syscalls are also interrupts. They're specific software interrupts that can be generated by a userspace process. On x86_64 this can be done via the syscall instruction, which, as per the manual:
"SYSCALL invokes an OS system-call handler at privilege level 0. It does so by loading RIP from the IA32_LSTAR MSR (after saving the address of the instruction following SYSCALL into RCX). (The WRMSR instruction ensures that the IA32_LSTAR MSR always contain a canonical address.)" - Intel Instruction Set Reference
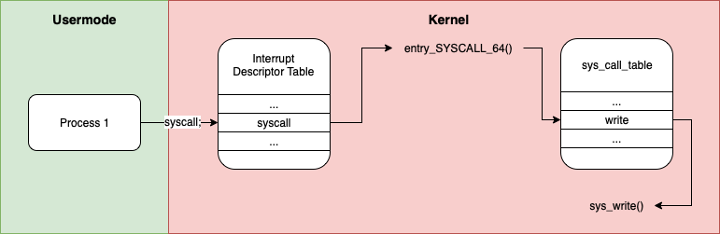
To summarize the process:
- Userspace process places arguments in registers and the syscall number in $RAX and executes the syscall instruction
- The kernel finds interrupt handler for the syscall interrupt in the IDT, entry_SYSCALL_64() in our example
- At this point, the usermode registers are saved onto the stack, defined by struct pt_regs
- The syscall number passed in $RAX is used as an index into the sys_call_table to find the right handler
- The correct syscall handler is run, we fetch and restore the usermode registers from the stack and the result is passed back to the user via $RAX
Syscall hooking
Back to business! Like I mentioned, our route to process context is achieved by employing a commontechnique: syscall hooking. The plan is to overwrite one of the function pointers in the sys_call_table with our own code, so next time that syscall is run, it runs our code.
Except, unlike some more typical use cases, we're going to use our hook to inject a usermode payload into the unfortunate process that calls our hooked syscall.
This is great because as remote attackers, we don't have much influence on the processes running on the target, but we can confidently assume certain syscalls are going to be called regularly.
So just like that, we've won! Okay, okay it's not quite as easy as that. There are a couple more hurdles for us to cross. First of all, to hook our syscall of choice we need to do a couple things in our shellcode:
- We need to kmalloc some memory for our hook & usermode payload to live; we then need to set_memory_x() our hook
- Next, we need to set_memory_w() the sys_call_table and also disable the write protection bit in $CR0
- Now we're able to overwrite one of the function pointers in the sys_call_table
Hooked!
So close! All that's left now is to write our actual hook and voil\u00e0. The aim here is to inject into a process with our usermode payload then pass control back to the original syscall handler like nothing happened.
The great thing about syscall hooking is that the syscall handler is passed a pointer to the struct pt_regs (step 3 above), which gives us access to the userspace registers. This means we can totally overwrite the instruction pointer.
We also have access to the current task_struct, meaning we don't have to settle for less; we can check the uid of the current process to make sure we're only injecting into root processes. No unpriv'd shells, thank you very much.
Overall, our hook will look something like this:
- getuid() to make sure we're hooking a root processes call; ignore if not root
- mmap() and executable region in userspace for our payload
- copy_to_user() our userspace payload
- Adjust struct pt_regs so that pt_regs->ip points to our userspace payload
- Clean up hook on success
- Return execution back to the original handler
Winning
Now it's all up to our imagination. We have an arbitrary userspace payload running in a root process, tucked away in our own little mmap()'d region. Just remember to clean up and return execution!
In our instance, a userland payload might look a something like the following pseudocode:
fork()
if (parent)
repair_registers() // E.g. RBP, RSP
jmp_old_ip() // hand back execution to original instruction ptr
else
CANVAS_callback() // establish connection with the CANVAS server
Mitigations
Before we wrap-up, I'd be remiss if I didn't touch on existing mitigations for bugs like CVE-2022-0435. So, here's a small glossary of relevant mitigations, including some we've already touched on:
- KASLR & CONFIG_STACKPROTECTOR are enabled by default on modern systems and both impose strict information leak requirements for remote attackers, given the limited surface
- CONFIG_FORTIFY_SRC: Since summer 2021 [6], adds strict memcpy() bounds checking to the Linux kernel. Essentially, this mitigation will trigger a fortify_panic() if we try to memcpy(dst, src, size), when we know that size > sizeof(dst/src) [7]
- CONFIG_FG_KASLR: As we've touched on KASLR, it's worth noting that Function Granular KASLR takes things a step further by randomizing the location of the kernel at a per-function level, rather than a single KASLR-slide
There are several architecture/compiler specific implementations that seek to provide control flow integrity (CFI) by protecting forward-edges (think function pointers) and/or backward-edges (think return addresses). These aim to mitigate control flow hijacking techniques, such as the ROP techniques we saw in this post.
On the topic of mitigations, I heartily recommend @a13xp0p0v's Linux Kernel Defence Map project to demystify the state of Linux Kernel security in a neat graphical format!
Conclusion
So, there we have it! A breakdown of writing a kernel remote using a recent vulnerability. Hopefully the post provided some insights into kernel exploitation and highlighted some of the differences to local exploitation.
It's been great to be able to share some of the incredible work I get to do at Apppgate Threat Advisory Services. If anyone has any questions, suggestions or corrections, please reach out to me at samuel.page@appgate.com.
Thanks for reading!
Creds
I'd like to give a huge shout out to my team lead, Alfredo Pesoli, for the encouragement, support and help along the way. Thanks to him and the team, I get to write cool stuff like this.
I'd also like to reference the 2011 talk "Anatomy of a Remote Kernel Exploit” by Dan Rosenberg as a great help for getting started on the remote exploitation path.
Reference
- https://www.sentinelone.com/labs/tipc-remote-linux-kernel-heap-overflow-allows-arbitrary-code-execution/
- https://blog.immunityinc.com/p/a-remote-stack-overflow-in-the-linux-kernel/
- https://lwn.net/Articles/569635/
- https://cateee.net/lkddb/web-lkddb/STACKPROTECTOR.html
- https://en.wikipedia.org/wiki/Supervisor_Mode_Access_Prevention
- https://forums.grsecurity.net/viewtopic.php?f=7&t=3367
- https://lwn.net/Articles/864521/
- https://github.com/torvalds/linux/blob/master/include/linux/fortify-string.h#L212